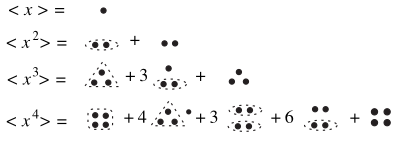A probability space consists of a sample space , such that for (some of the) events , we assign a probability so that
, and
if are disjoint events, then .
basically the usual countable additivity
Definition
The objective probability obtained experimentally from the relative frequency of an occurrence in many tests of the random variable
where is the number of times a random process is repeated and represents the number of times event occurs in those repetitions. Clearly the bigger the the more accurate
Definition
A real random variable is a map , which can also be defined by a cumulative distribution function
Definition
The expectation value of a function , denoted , is
One specific example is the moments of a random variable X, which are
Definition
The characteristic function of a random variable X is
and because this is a fourier transform we may obtain the distribution function via fourier inversion theorem
now doing a taylor expansion on the characteristic function
The Taylor series of about is:
We need to compute the derivatives .
Differentiate under the integral (justified for well-behaved ):
The partial derivative is:
So:
Evaluate at :
where is the -th moment. So we have
Definition
the cumulant generating function is the logarithm of the characteristic function.
Proposition
We have
and that we may see the nth cumulant as a connected cluster of n points and the mth moment as the sum of all subdivision of m points into partitions of smaller clusters
first by definition we have
we may rewrite the RHS as
for each expand the indivdual exponential using its taylor series
simplify to get for each
so altogether we get
now we equate the coefficients of in which case for each the contribution by the LHS and RHS respectively is
rearranging this gives the desired result
now simply counts the number of ways to break points into clusters/partitions of points where each value represents the multiplicity of a partition of size .
Remark
Above it also serves to select chosen values of for each . Then simply multiplies these pre-selected set
next notice that for each chosen way of partitioning we divide by and as we don't want to repeat count clusters and the balls in each cluster
Example
graphically
corresponds to
2.3 Some Important Probability Distributions
Definition
the normal(gaussian) distribution describes a continuous real random variable with
Proposition
the corresponding characteristic function is then
proof: essentially group all terms into a quadratic form so that we may apply the standard gaussian integral result. Specifically we first expand the exponent
then letting the terms in the paranthesis be we rearrange to get
basically with the goal of separating the from the constants in the exponent. Then finally to get the gaussian integral form we need a quadratic factorization of so we do complete the square in the paranthesis to get
we sub back into the constant part
and then separate out and the constants in the exponent as desired
as planned we recognize the gaussian integral form in the integral on the right and therefore we have
and so cumulants are in the form
so it is clear by comparing with the definition above that
in which case calcuation of moments from the culmulants using the previous proposition is just
Definition
the binomial distribution consider a random variable with two outcomes and of relative probabilities and then the probability occurs times in trials is
note that we have
then our characteristic function is given by(the 3rd equality follows because the LHS is simply the binomial expansion of the RHS)
and consequently our cumulent generating function is
Definition
the poisson distribution
2.4 Many Random Variables
Definition
the **joint PDF ** is the probability density of an outcome in a volume element around the point
in other words, letting be a vector of random variables:
the joint PDF is normalized such that
if and only if the random variables are independent the joint PDF is then the product of individual PDFs
Definition
the unconditional PDF describes the subset of random variables independent of the values of others. For example you are only interested in the first variables of the total variables then:
where effectively we have integrated over all the other non-relevant variables for each .
Observe that now our PDF does not depend on the variables as they are automatically included for any . For example say we have position vector and we are only interested in . The unconditional PDF simply includes all probability density contributions over for each so our PDF is independent of
Definition
the conditional PDF describes the behavior of a subset of random variables for specified values of others. For example consider where is the joint PDF and that is the conditional PDF for velocity at a given fixed position
note we have , a normalization factor that ensures
so we have
where the final equality follows because the 2nd expression is simply the definition of unconditional PDF as defined just previously!
Proposition
Essentially we have just shown that Bayes' Theorem
Definition
the expectation value of a function is obtained as before from
and the joint characteristic function will then be the N-dimensional Fourier Transformationn of the joint PDF
like before we do a taylor expression but this time for a multivariate case
we may now apply the multinomial expansion given by
where we may sub into our expression to get
with this we may rewrite our characteristic function like so
where (inside is a product btw). With these the following should make sense
Example
consider
Example
and consider in general
similarly for cumlants we have
which should make sense if you recall how cumulants are defined.
Example
The same "points in bags" argument for relating cumulants and moments works here: if we want to put two 1s and one 2 into bags, the different configurations are (112), two ways for (1)(12), one way for (2)(11), and one way for (1)(1)(2), so
Proposition
The joint gaussian distribution in N dimensions is given by
Proof: first recall the univariate gaussian distribution but this time suppose we have N independent univariate guassian random variables each with its own mean and variance . The PDF for each is then:
since they are independent we have for
which we may simplify to
in matrix form we may write
where and . Therefore we may also rewrite this as
as for the characteristic function first recall that
so substituting the join PDF we obtain
now for each recall from earlier we should then get
finally to get the matrix form we first define the mean vector and wavevector . The linear term is
For the quadratic term, since variables are independent, the covariance matrix is
diagonal:
Wick's theorem says that suppose we have a multivariate Guassian with then
proof: study quantum field theory first...for now just assume this
We now will like to consider functions of random variables. First consider
where and is the indicator function that returns if is in the range and 0 otherwise. We can rewrite this as
now because is arbitrary then have
with this relation we may easily generalize to multi-dimensions like so
Example
Let , where are independent random variables.
Then we can write the probability distribution function as
and this can be simplified most easily by using a (polar) change of variables: set
so that and . Then
and now we can plug in (in polar coordinates, r is always nonnegative) wherever it appears to get
and we've removed the delta function from the expression.
3 Kinetic Theory of gases
Kinetic theory studies the macroscopic properties of large numbers of particles, starting from their (classical) equations of motion.
First we consider how to define "equilibrium" for a system of particles. Consider a dilute(nearly ideal) gas.
At any time , the microstate of a system of N particles is described by specifying the positions and momenta of all particles.
The micostate corresponds to a point in the 6-N dimensional phase space
Fact
Thee time evolution of this point is governed by the canonical equations
where the hamiltonian describes the total energy in terms of the set of coordinates and momenta
Now as formulated within thermodynamics the macrostate M of an ideal gas in equilibrium is described by a small number of state functions such as .
Fact
Many different microstates can represent the same macrostate(i.e a many to one relationship).This is because particles can be arranged in countless ways (positions and velocities) while still giving the same average properties like temperature or pressure
Consider copies of a particular macrostate each described by a different representative point in the phase space .
Definition
A phase space density is defined by
to make sense of this essentially there are microstates in the phase space . There are microstates contained the infinitesimal area around the point . Therefore represents the objective probability(defined above)
knowing this it is then clear that we must have when integrating over the whole phase space for to be a properly normalized probability density function. With these we now define
Definition
Essemble averages for an arbitrary function
Definition
When the exact microstate is specified the system is said to be in pure state
On the other hand when our knowledge of the system is probabilistic in a sense that it is take from an density with density it is said to be in a mixed state
3.2 Liouville's Theorem
Theorem
Liouville's theorem states that the phase space density behaves like an incompressible fluid
First consider
In the time interval we have like so
which is essentially a taylor expansion 1st order.
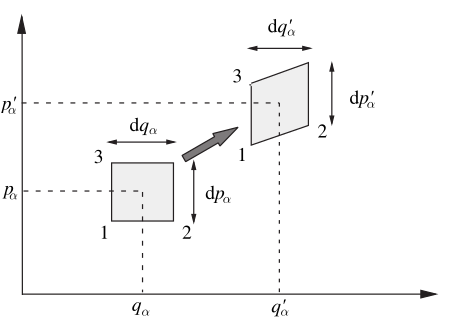
Now consider the case for first. Let 2 points separated by . Then take their time evolutions after :
For Point A:
For Point B:
Since is small, expand around :
Plug this into Point B's evolution:
Substitute the expressions:
Simplify and doing everything we have done so far for for we get
we note that but we have
However the time evolution of coordinates and momenta are governed by canonical equations where we have
therefore
that is or that in we had but the volume that occupies is the same
Fact
more precisely behaves like the density of an incompressible fluid
The incompressibility condition can be written in differential form as